


Web2GPT 安装教程|飞牛NAS Docker 本地部署,一键让传统网站变AI 智能应用
各位网站主理人,你有没有想过,让自己的网站像真人一样和用户对话?
我最近试了长亭科技的 Web2GPT,确实好用:把现成的传统网站,一键“包”成能对话的智能应用,效果有点像 ChatGPT,但用在你自己的网站业务上。
想象一下:企业官网、知识库、产品手册,不再是一堆静态文字。用户直接发问,系统就能从你的网站内容里“掏”出答案。喂内容也不麻烦:能自动抓取整站、抓单页、传文件,甚至手动补充,几种方式随你挑。学完之后,放到网页挂件里,或者接到钉钉、飞书、企业微信的机器人,都很顺畅。
我这个人做事讲效率,也看重安全。雷池 WAF 我一直在用,Web2GPT 的思路和配置都比较清楚,上手不费劲。下面就是我整理的图文教程,按步骤带你把网站变成能对话、能办事的应用,让用户不用再满站点翻来翻去找信息。
一、Web2GPT 介绍
Web2GPT 是由 长亭科技 推出的面向网站管理员的智能 AI 应用,可以将 传统网站 一键包装为 智能 AI 应用。
名称的含义:Web2GPT(读作 Web to GPT),顾名思义,它可以基于一个 Web 网站中的业务内容,自动生成类似 ChatGPT 的 AI 应用。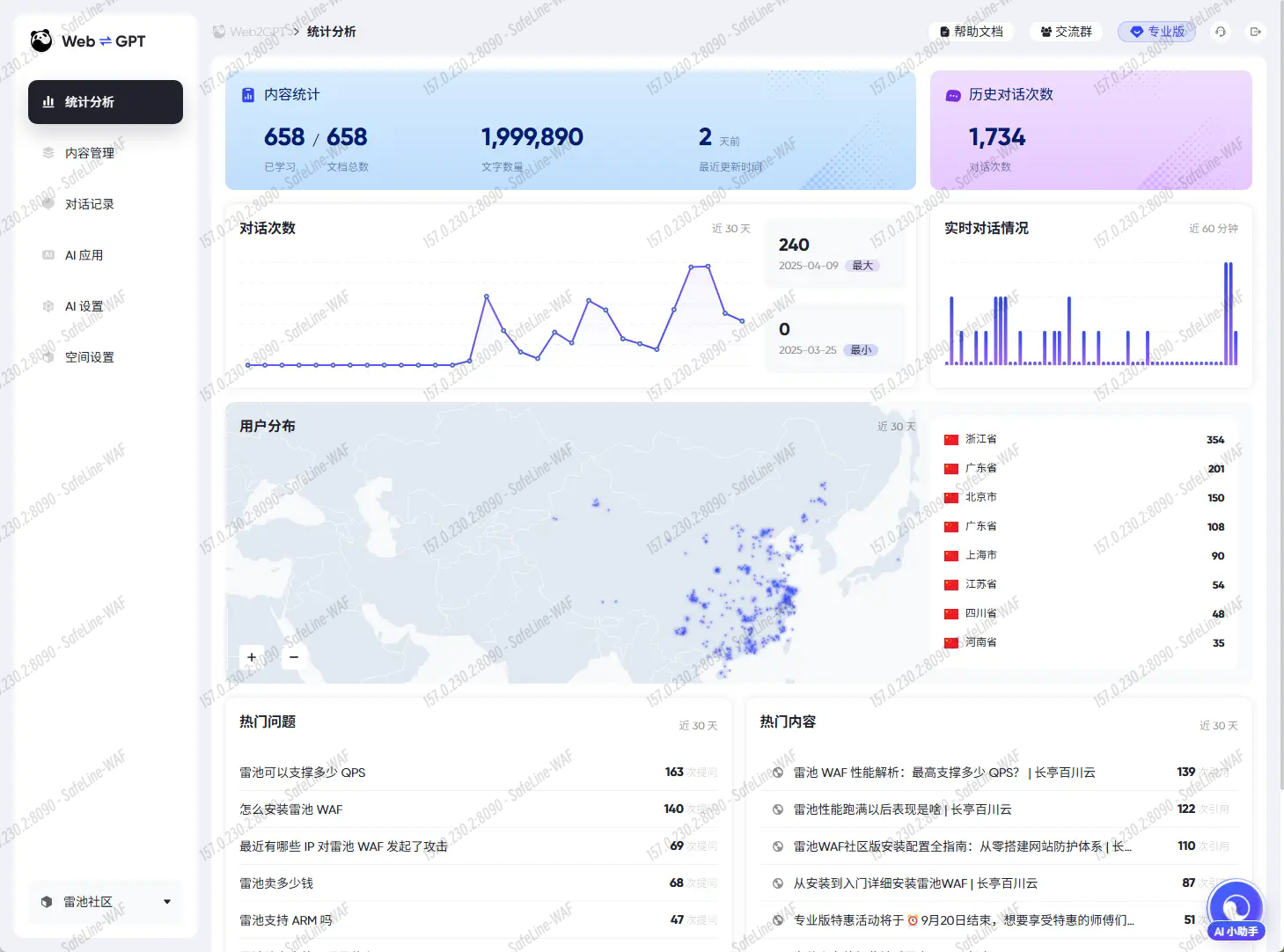
核心能力
智能问答:自动理解你的网站业务,作为业务专家回答问题。
智能操作:根据自然语言,帮助用户自动完成业务操作。
快速集成:支持网页挂件、App 挂件、微信/钉钉/飞书机器人等多种接入方式。
只需 三步,5 分钟,让你的网站拥有专属 AI 助手:
采集内容:输入网站地址,Web2GPT 自动采集网站内容。
学习知识:选择有效内容,交由 AI 学习。
创建应用:基于学习内容,创建属于你的网站 AI 应用。
二、Web2GPT 能干什么
Web2GPT 结合大模型技术,会根据网站地址自动梳理内容与交互逻辑,生成可快速集成的 AI 应用。
典型场景
1. 智能客服
提供业务素材,Web2GPT 自动学习并充当在线客服,支持 网页、钉钉、微信 等渠道。
2. 站内搜索
解决传统搜索引擎收录不及时、效果差的问题,提供优质的 语义化搜索 体验。
3. 自动化操作网站
支持自然语言操作网站。
例如:
“嗨,Web2GPT,我的学号是 123456,帮我报名下周二的英语六级考试。”
三、Web2GPT 的特色
无需人工整理知识库:自动学习网站内容
无需关注 RAG 流程:自动适配最佳状态
快速集成:支持微信、钉钉、飞书
可追溯:使用过程可被快速记录,方便管理员分析
四、安装要求
操作系统:Linux
依赖软件:Docker ≥ 20.10.14,Docker Compose ≥ 2.0.0
CPU:最低 2 核,推荐 4 核及以上
GPU:无需 GPU(需外接大模型)
内存:最低 4GB,推荐 8GB+
硬盘:最低 10GB,推荐 20GB+
五、部署教程
以下以 飞牛NAS系统 为例(其他系统请自行安装最新 Docker、Docker Compose)。
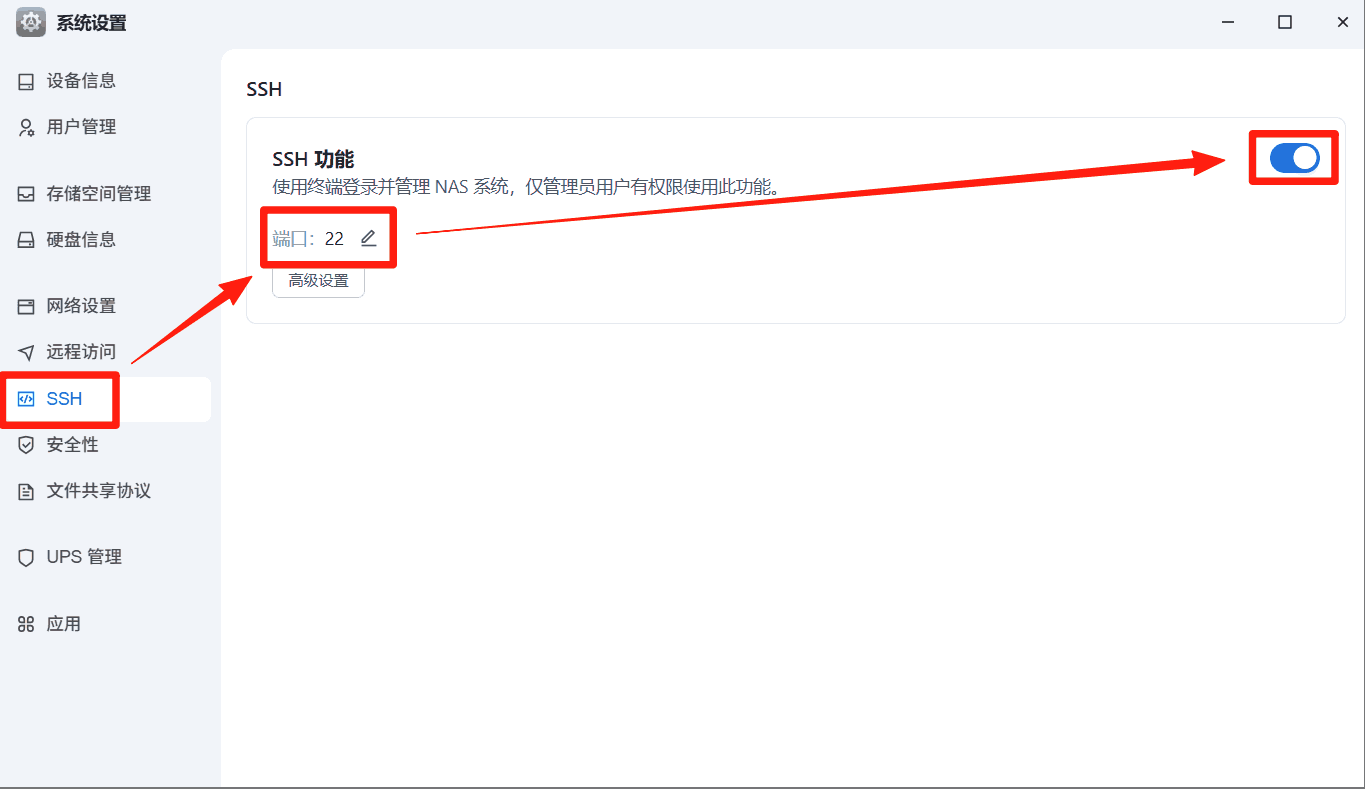
打开飞牛的SSH功能,使用终端软件进行连接,并切换到root状态下。
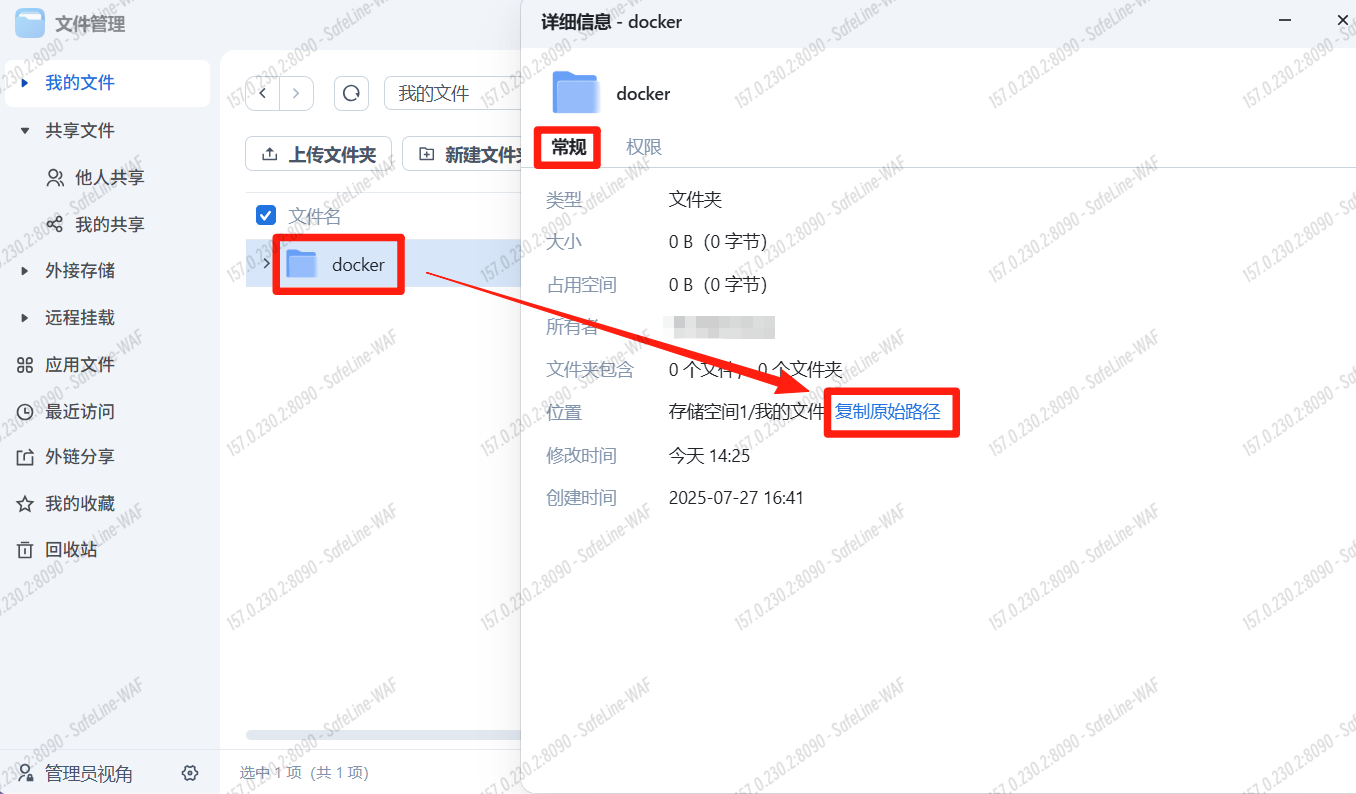
点击docker文件夹>右键>详细信息>常规>复制原始路径(演示将所有项目都放在了docker文件夹)
进入docker文件夹内
# 将 /vol1/1000/docker 换成你实际的文件夹路径 cd /vol1/1000/docker创建项目文件夹及子文件夹
mkdir -p web2gpt/{data/minio,data/nats,data/postgres,data/qdrant,data/redis}下载 docker comopse 文件
curl https://release.web2gpt.ai/latest/docker-compose.yml -o docker-compose.yml下载环境变量模版文件
curl https://release.web2gpt.ai/latest/.env.template -o .env初始化配置文件(全部复制后一次性粘贴)
count=$(grep -o "{CHANGE_TO_RANDOM_PASSWORD}" .env | wc -l); for i in $(seq 1 $count); do sed -i .env -e "0,/{CHANGE_TO_RANDOM_PASSWORD}/s//$(openssl rand -base64 20 | tr -d '/+=' | cut -c1-20)/"; done编辑.env文件
vi .env按字母
i键进入编辑模式,修改下面的配置文件,按Esc键退出编辑模式,输入:wq保存并退出。(排版太挤的就先粘贴到文本文件内,修改后再使用,灵活应变。)
# 服务地址(钉钉等组件) ORIGIN=http://localhost:9999 # 自定义组件的访问端口,可自行修改。 # 中间件密码----下面这几个可以看下一步教程随机生成后替换掉,按需执行。 POSTGRES_PASSWORD=np7hqNyQB5sRle6FHi4o NATS_PASSWORD=Rte53HcYdyKgWb4kVEu0 JWT_SECRET=0jL7yCvXUdSuX12FFCWH S3_SECRET_KEY=vrFXDUhzkkE7vBygsOik QDRANT_API_KEY=89mZgMQBP2sdFVelXD2O REDIS_PASSWORD=zjRChgr5g4qaX5Xzqqex # 管理后台登录密码 ADMIN_PASSWORD=DHcSoHT4ugwokOGEEvej # 管理后台的管理员密码,现在修改,系统内无修改功能。 # 管理后台访问端口 ADMIN_PORT=9999 # 管理后台的访问端口,可自行修改。生成一个 24 字节(经过 base64 编码后更长)的随机字符串
# 生成一个 24 字节(经过 base64 编码后更长)的随机字符串: openssl rand -base64 24 # 如果你只要字母数字,可以再过滤: # 👉 生成一个 20 位的大小写字母+数字 随机串: openssl rand -base64 24 | tr -dc 'A-Za-z0-9' | head -c 20查看当前项目文件夹路径
pwd授权该项目文件夹内的读写权限【部分NAS系统需要(如群晖),否则容器无读写权限访问运行,按需执行。】
# 将 /vol1/1000/docker/web2gpt/ 换成你自己实际的文件夹路径 chmod -R 777 /vol1/1000/docker/web2gpt/执行命令,启动docker-compose模板文件,拉取镜像并创建容器。
docker compose up -d 或 docker-compose up -d查看正在运行的项目容器实时日志,按
Ctrl+C中断查看。docker compose logs -f 或 docker-compose logs -f
六、使用 Web2GPT
1. 访问控制台
打开浏览器,以NAS的IP+设置的端口号进行访问。
以本机为例:http://192.168.2.6:9999
默认账号:
用户:
admin@web2gpt.ai密码:见
.env文件ADMIN_PASSWORD变量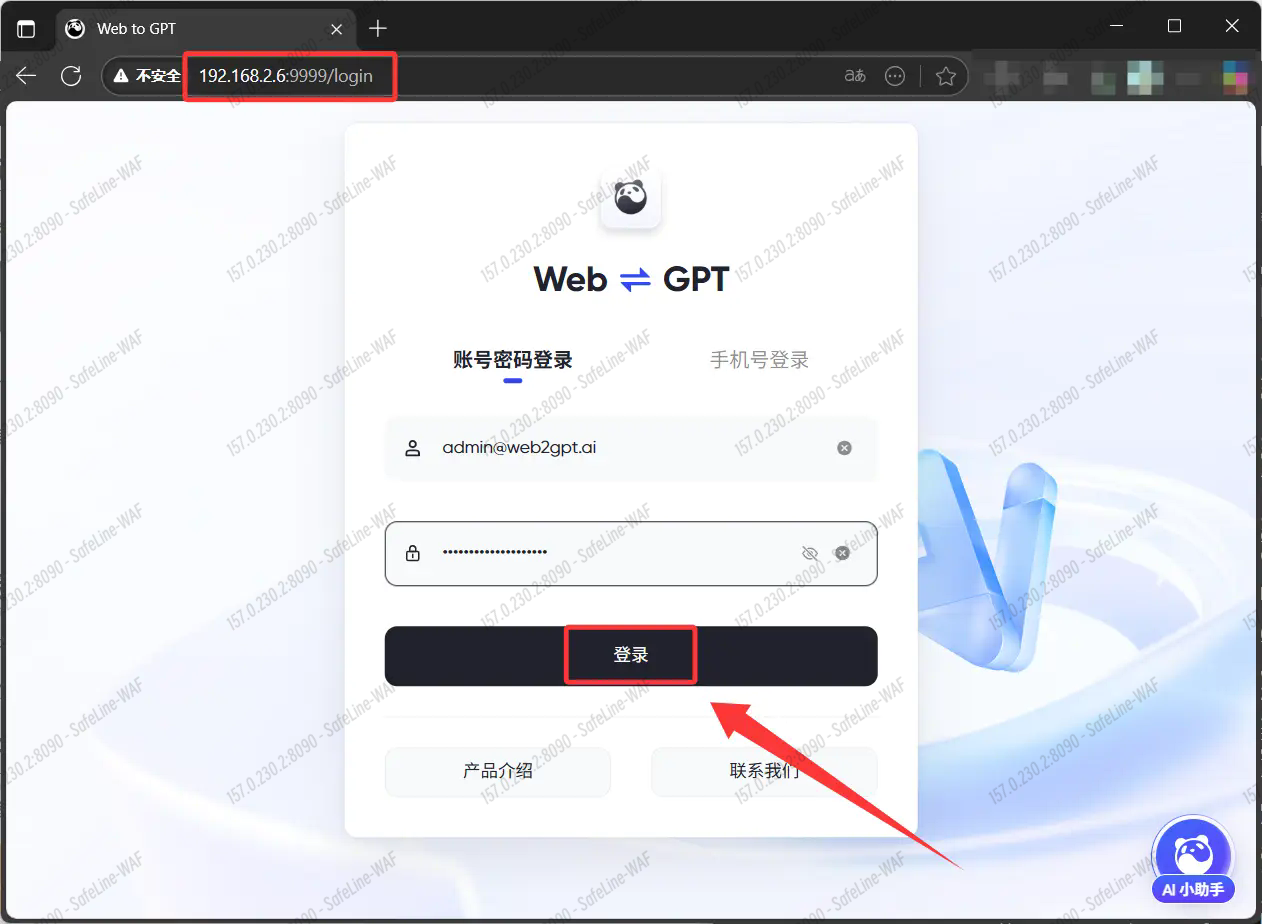
登录成功
2、AI 设置
Web2GPT 离线版本需 接入第三方模型。
我们以【硅基流动】为例,它支持注册即送额度,适合入门(其他的得先充钱才能用💰),点此直达跳转领免费额度的注册地址。
快速注册后进入后台,点击账户管理 > API 密钥 > 新建 API 密钥。
创建新 API 密钥,复制备用。
点击AI设置--添加第三方AI模型
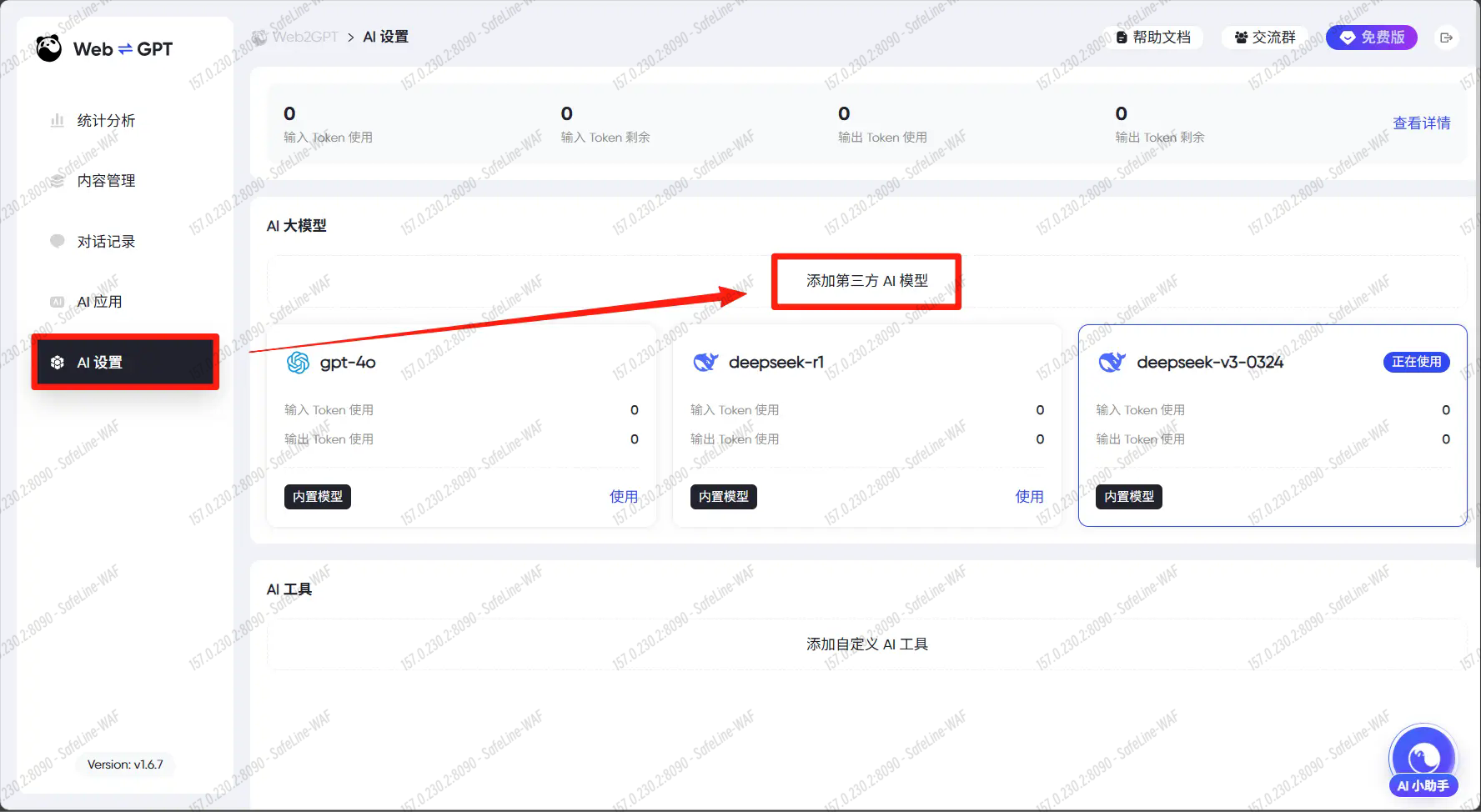
选择硅基流动,粘贴我们的API密钥,选择你想使用的AI模型,然后点保存。
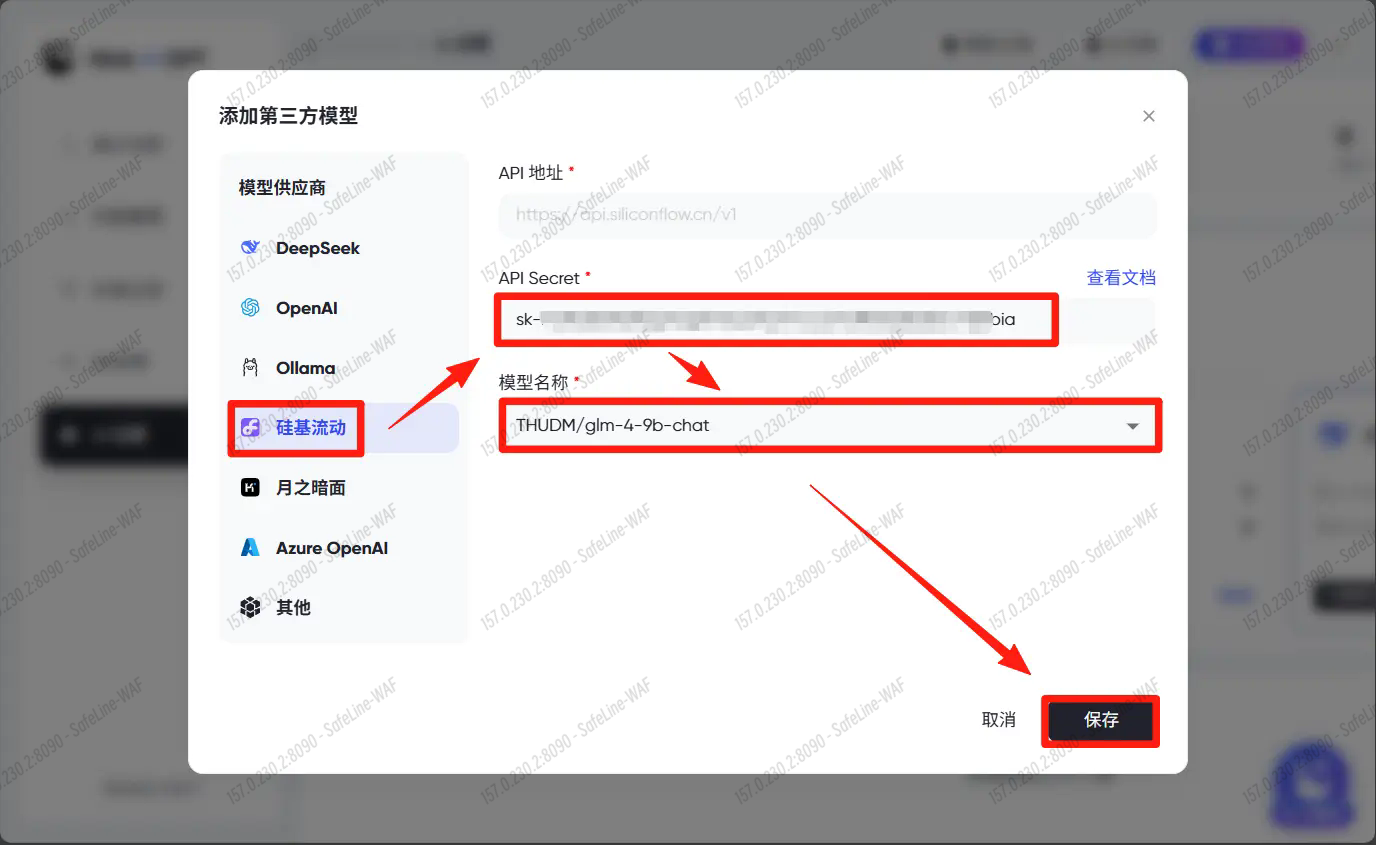
AI 模型添加成功,点击使用。
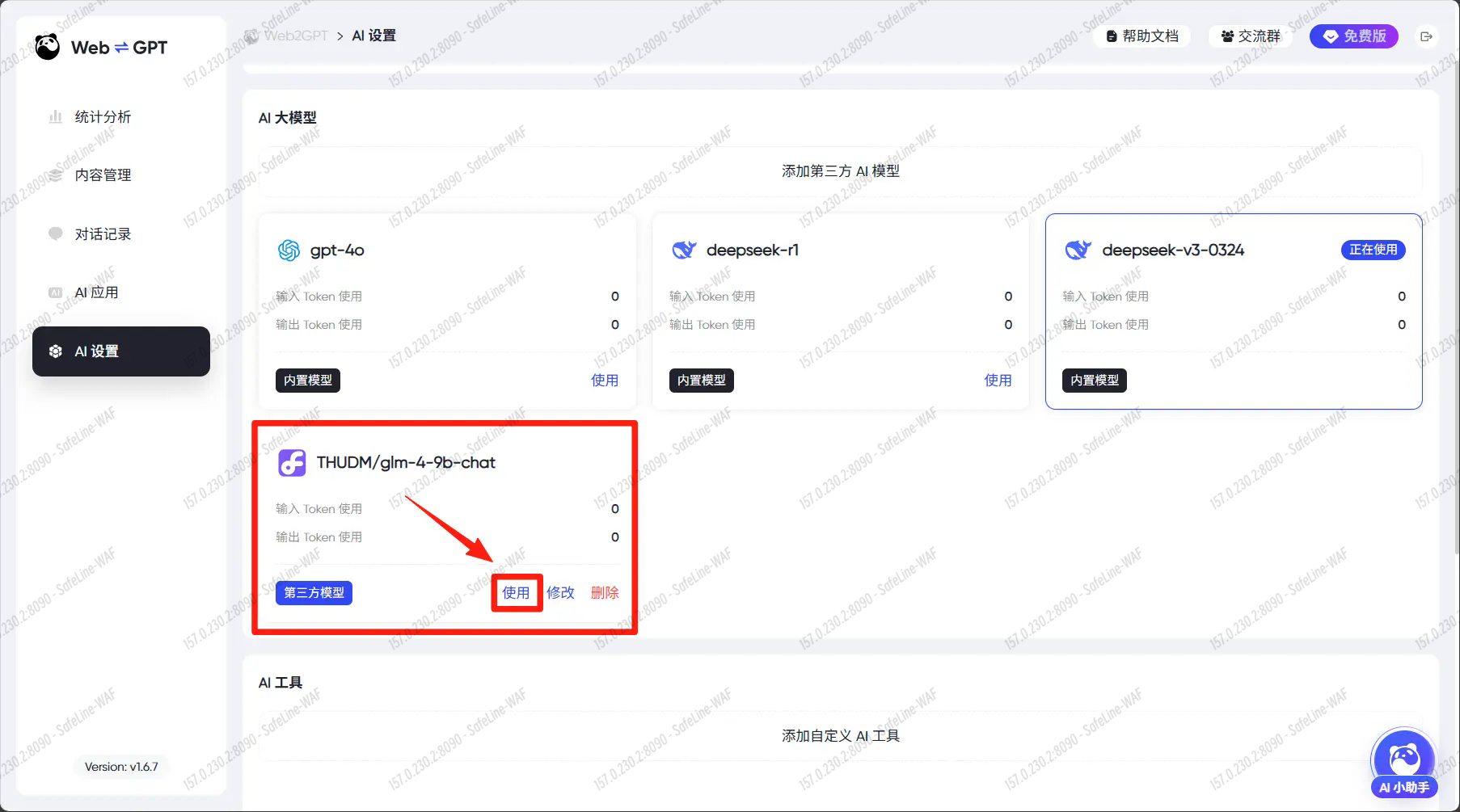
3、抓取知识库内容
进入 内容管理 > 自动发现 > 配置
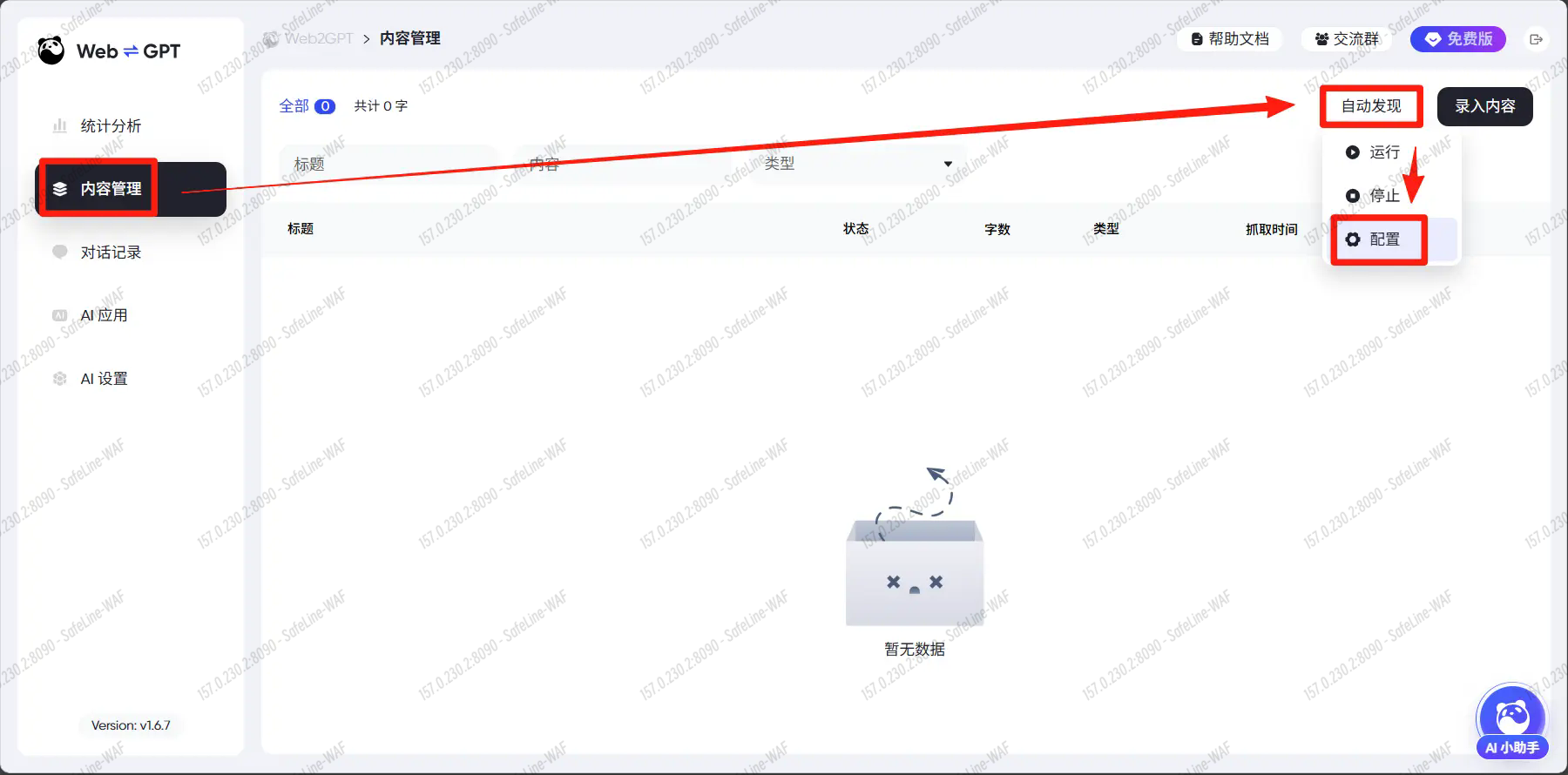
粘贴目标网页地址,点击确认。
演示就以爬取本站为例,但你不要填写本站地址,不然会被防火墙自动拉黑并同步到雷池WAF全球黑名单数据库中。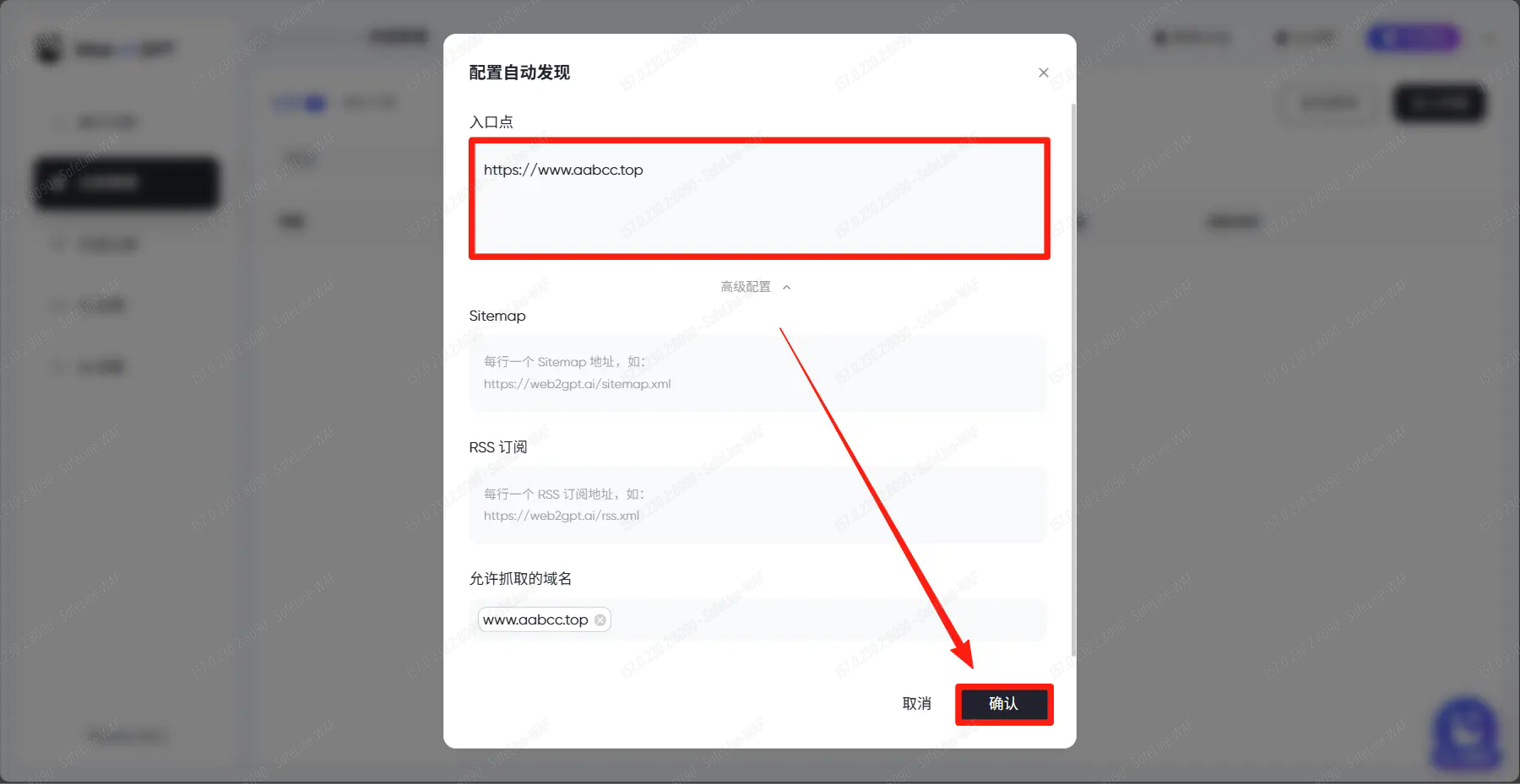
添加完成之后会自动开始抓取全站内容,等待全部抓取之后你可以全选,点击学习。
系统只会抓取公开的文字内容,任何限制了访问的或者非内容页面均不会被抓取。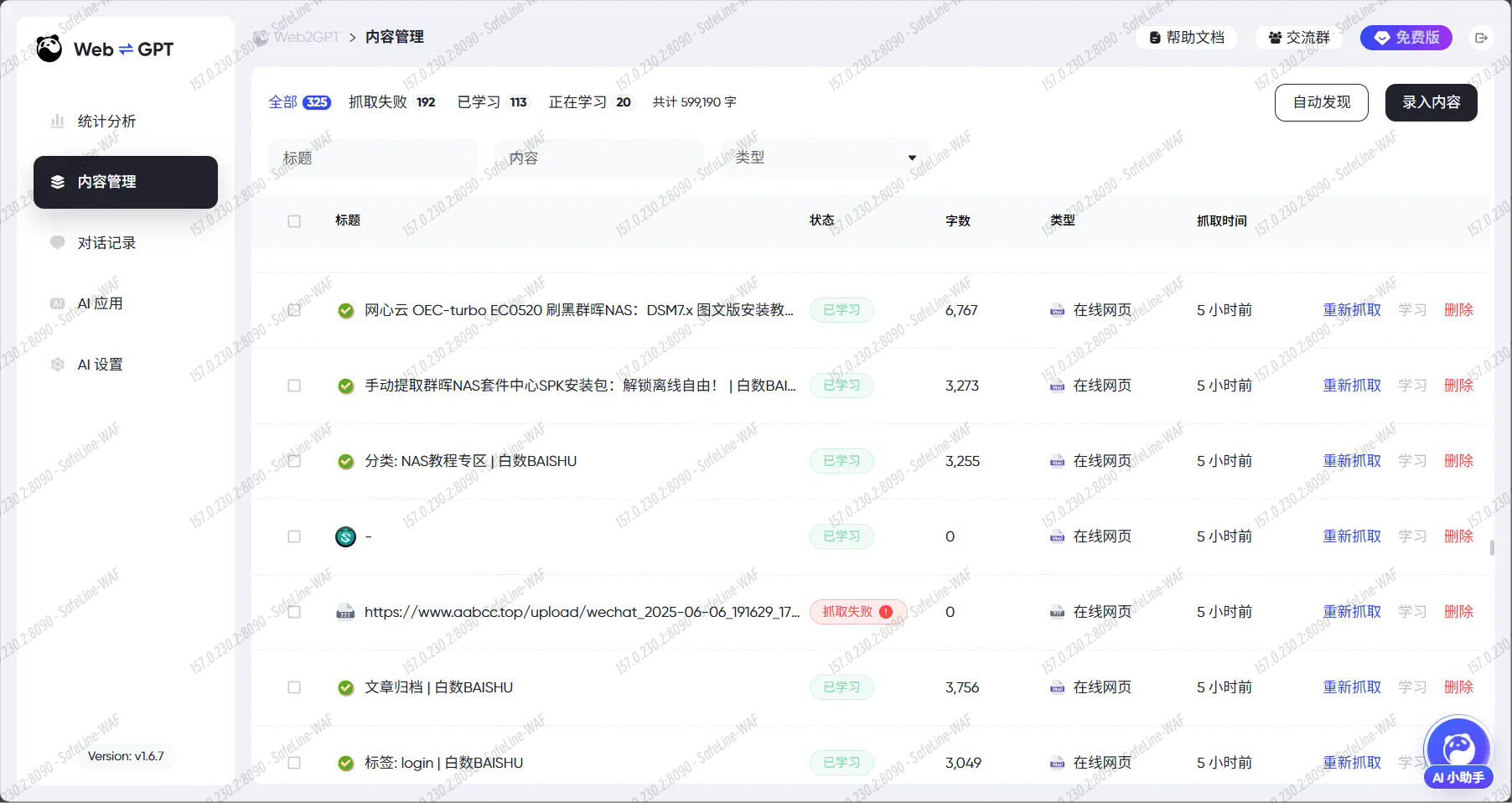
注意:学习过程会消耗 CPU 性能,低性能 NAS 需耐心等待。
4、创建 AI 应用
点击 AI应用 > 创建AI应用
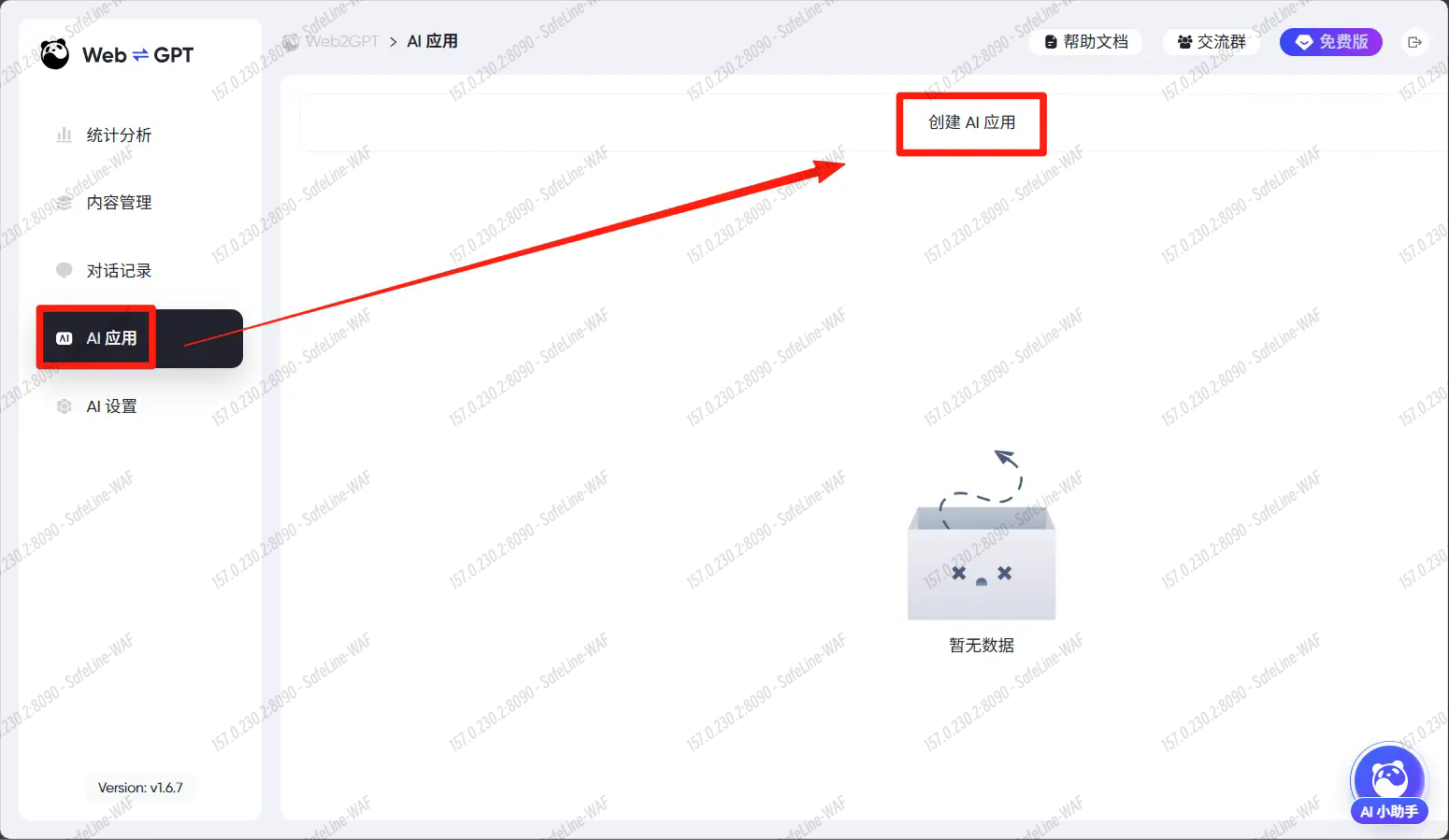
设置一个应用名称,选择你需要使用的应用类型,然后点击确认。
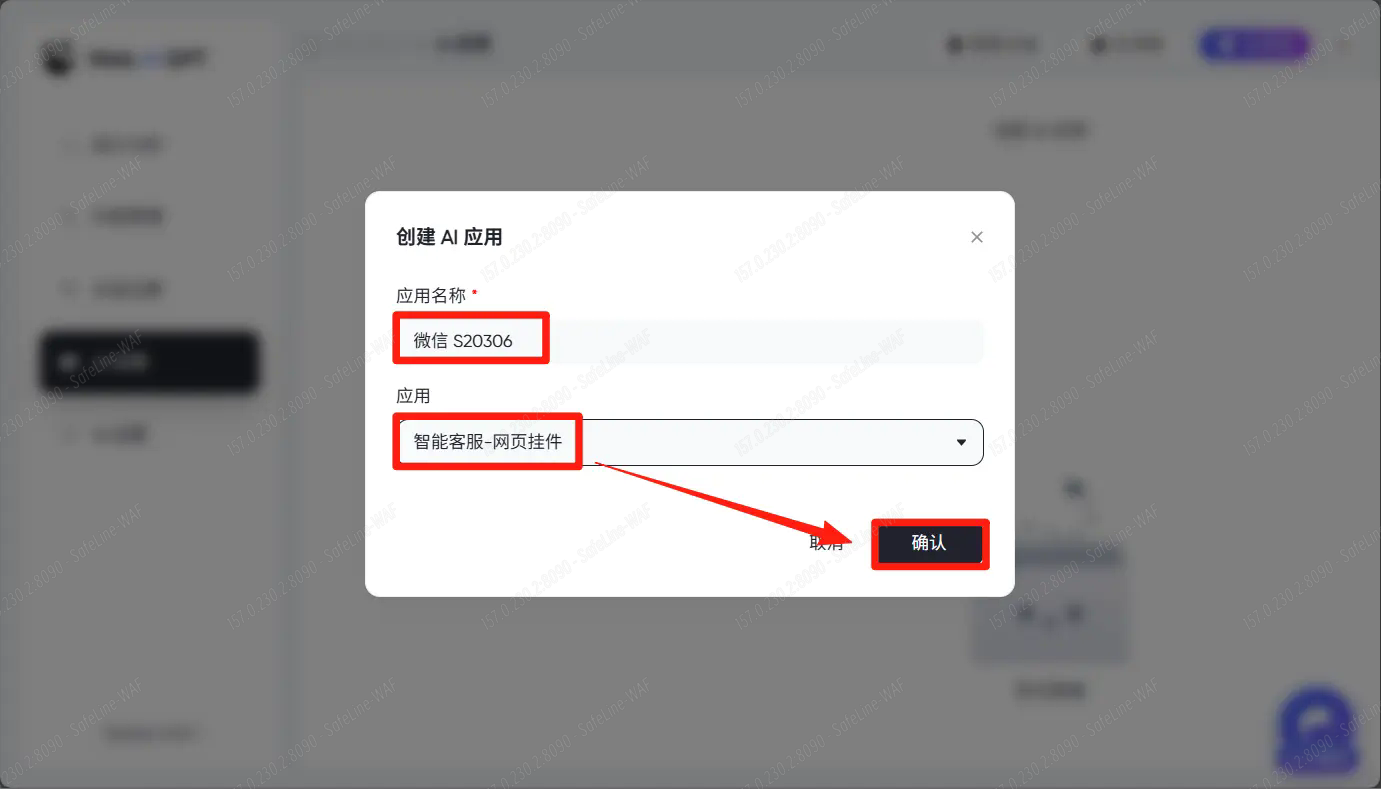
按提示填写信息后点击保存
(因为我们是创建的网页挂件服务,所以我们复制显示挂件代码,粘贴到你的网站上即可。如果是对外服务的网站就将地址换成域名。)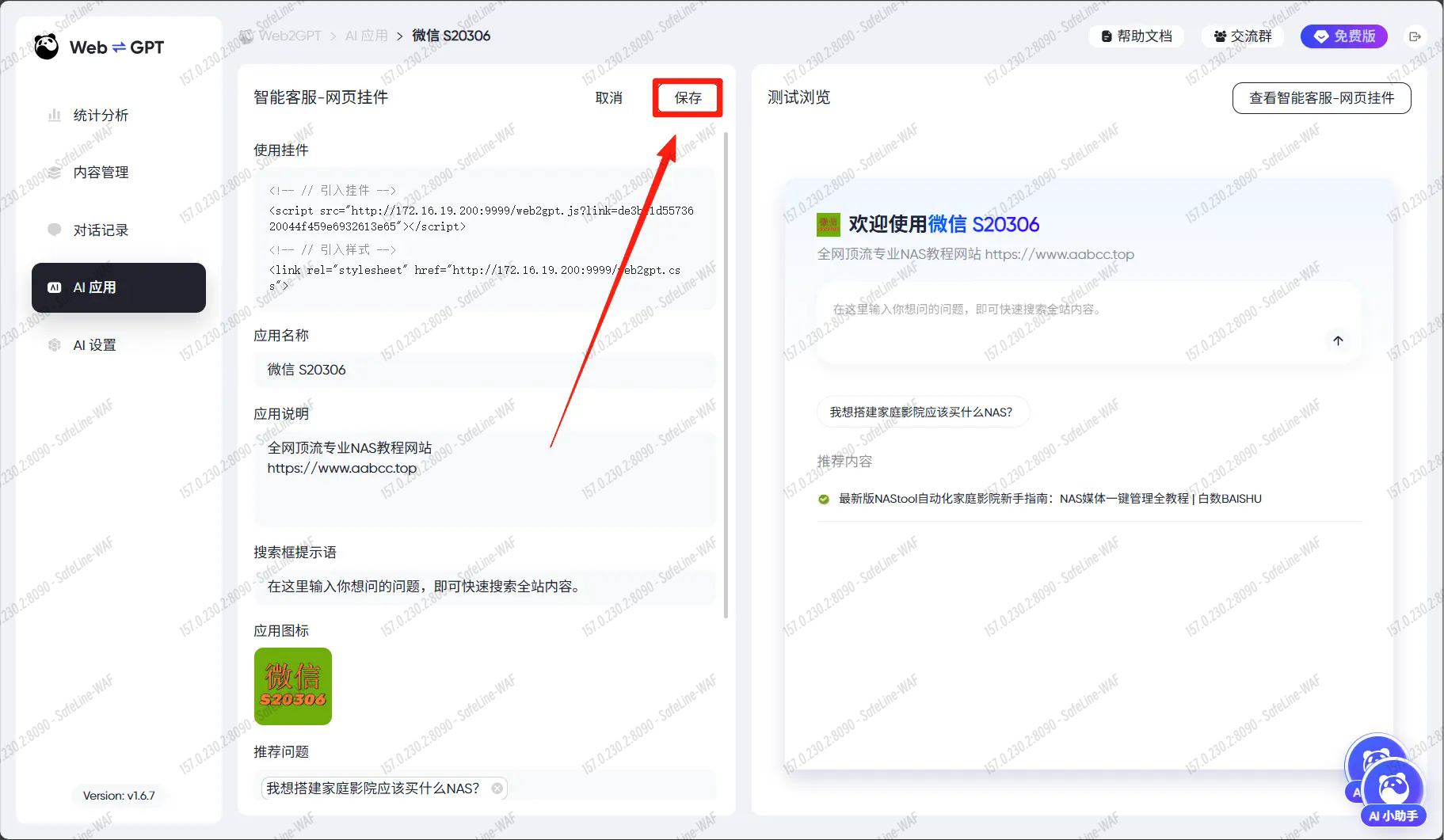
5、测试效果
点击开始使用测试一下
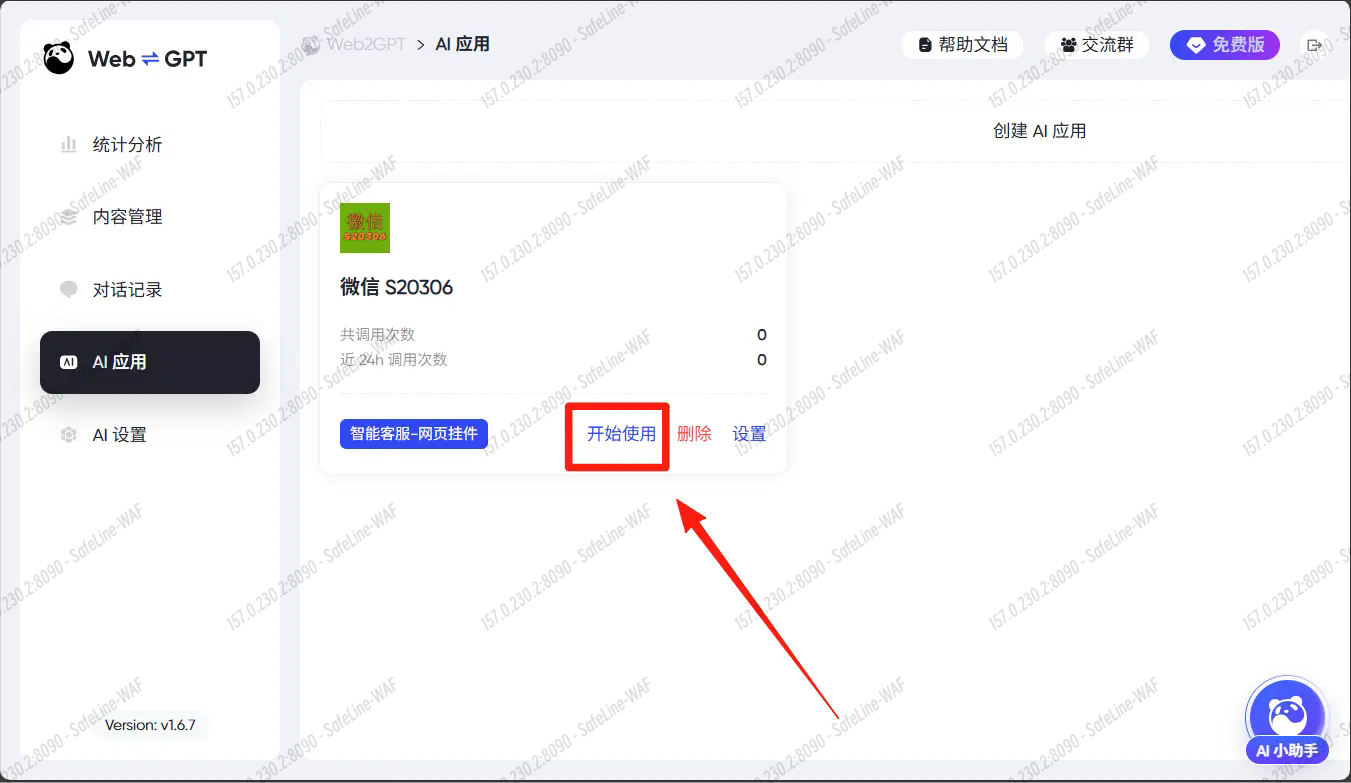
点击右下角挂件,输入你想问的问题。
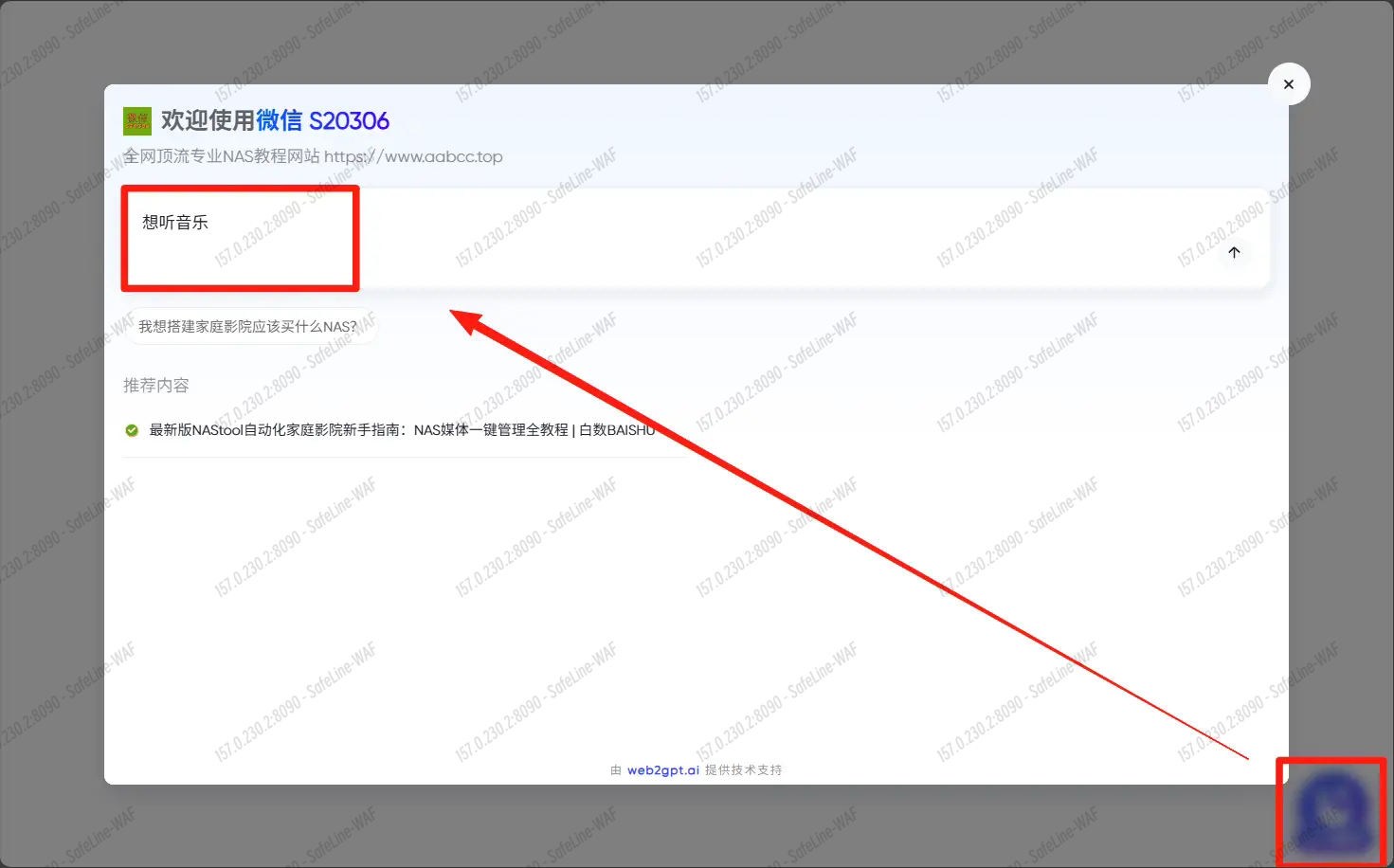
稍等一下即可检索成功并给出推荐的网页地址
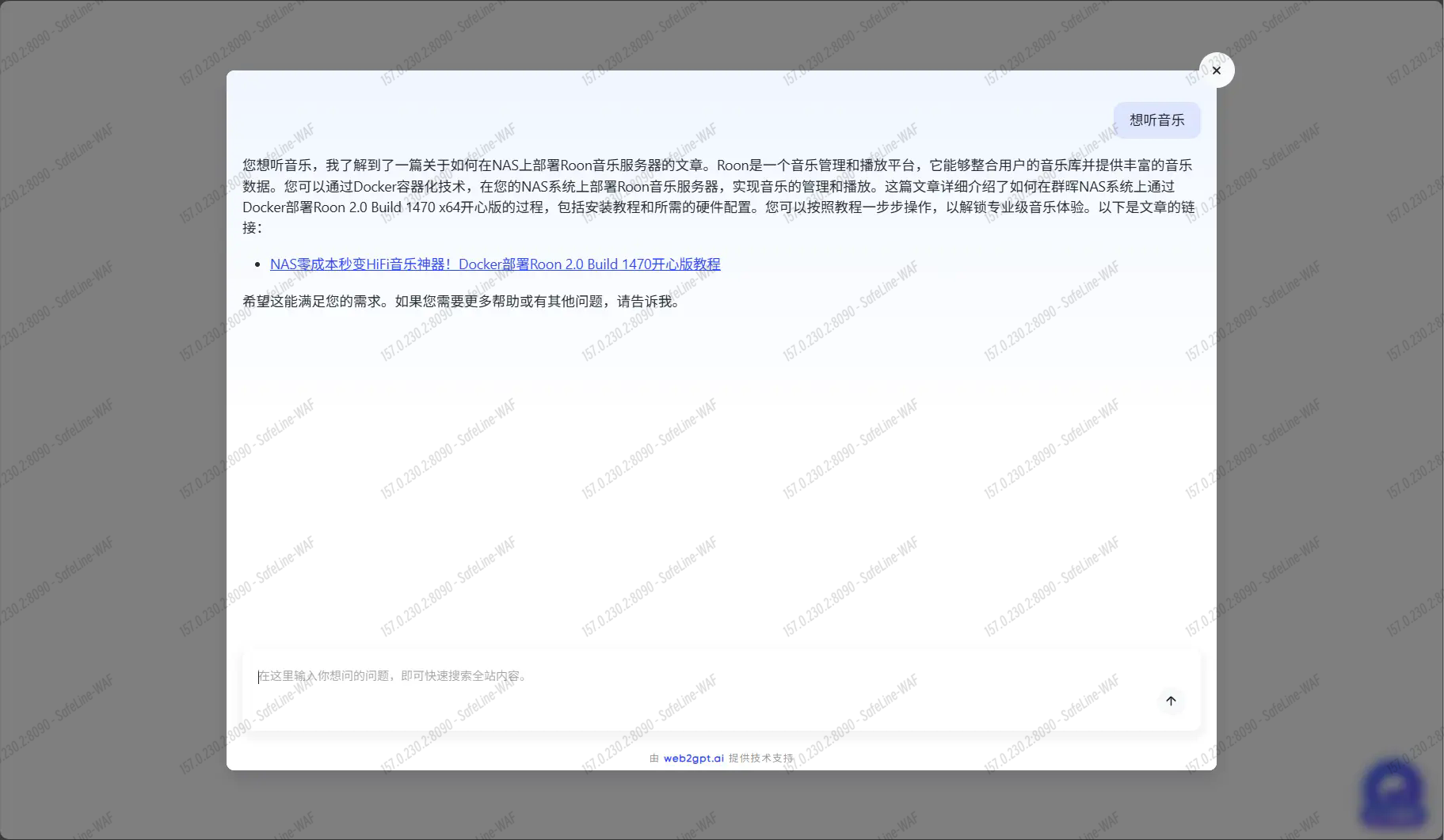
剩下的就是按你自己的需求去使用了
例如和本站教程的PandaWiki知识库搭配+爬取其他公开访问网站+手动上传内部文件,即可快速创建专业领域的内容索引、快速匹配教程、智能回答。
七、Web2GPT 部署总结与最佳实践
通过本文教程,你已经学会了如何在 飞牛NAS 或其他 Linux 环境下,基于 Docker + Docker Compose 快速部署 Web2GPT。整个过程仅需三步:
采集网站内容,自动构建知识库
接入第三方大模型,让 AI 真正理解业务
创建 AI 应用,通过挂件或机器人快速集成到业务系统
在实际使用中,推荐的最佳实践包括:
优先选择高质量知识源:减少噪音内容,提高 AI 回答准确率
合理分配 NAS 资源:至少保证 4 核 CPU 和 8GB 内存,避免长时间抓取时卡顿
结合业务场景落地:典型应用有智能客服、站内搜索、自动化表单操作等
做好安全配置:及时更换
.env文件中的默认密码,防止被暴力破解
Web2GPT 本质上是一个 面向传统网站的 AI 中间层,能够让网站快速升级为智能化应用,降低运维和开发成本。
如果你希望让企业官网、学校网站或社群平台快速接入 AI,Web2GPT 是一个即装即用的解决方案。
八、相关地址
文末

👇👇👇
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
- 免费云服务器资源,最高配置可达4核8G
- 企业级安全防护,DDoS防护与免费SSL证书
- 高速SSD存储,数据读写性能提升300%
- 24/7专业技术支持团队,随时解决问题
- 助力50,000+用户搭建高性能云服务